building a cluster from low cost parts
what?
This project was an experiment in constructing a cluster from low cost parts. A 2 gigaflops system of 10 nodes, with 1.6 gigabytes of total RAM and 10 gigabytes of total hard drive storage was built on a 100 Mbps Ethernet network at a cost to the authors of approximately $450 (after rebates). A head node with a single hard disk is used to boot the remaining 9 diskless client nodes over the network. OpenMosix is used on a Debian Linux operating system to provide an easy to use and manage single system image clustering environment. The final ClusterFLOP is meant to be a proof of concept with results that are scalable to compete with larger-scale parallel computing systems.

why?
The classical approach to improving computing performance has been to "make it faster". Competing manufacturers have played a game of oneupsmanship, reducing process sizes and increasing processor operating frequencies. This ideology allows consumers to purchase the latest and greatest processing power at a premium. Large-scale parallel computing systems have typically been constructed from such high-end components. However, recently there has been a branch away from using the best (and most expensive) components available towards using lower cost, mid-grade parts. This new concept of parallel computing has become more about using readily available resources to perform the same operations at a reduced cost.
The introduction of Local Area Network (LAN) switches has resulted in the ability to create scalable massively parallel computing systems with high network bandwidth from off-the-shelf components, instead of having to rely on custom systems and custom networks. The use of standard parts also allows for a much less expensive implementation of a parallel computer. Since a cluster consists of separate computers connected through a networking infrastructure, replacing or repairing a node does not mean that the entire cluster has to be taken offline. Repair may be as easy as unplugging the defective node, without affecting the operation of the rest of the cluster, and connecting a new node.
One disadvantage to running a cluster has been the absolute cost of owning one. Managing a cluster of N nodes can be close to the cost of managing N separate computers. However, a better measurement is cost for performance. A cluster can have the same performance as a large-scale proprietary parallel computer, but can cost less due to the use of highly available parts. Large-scale proprietary parallel computing systems are produced in small volumes using specialty components, resulting in higher development fees being incurred per system. A cluster is composed of commodity parts, produced in large volumes for general markets and not specifically supercomputers, resulting in much smaller development costs being passed onto the purchaser.
who?
The graduate students who constructed and tested the ClusterFLOP are David Feinzeig, Jeremy Slater, and Stephen Laverty. Project assistance and laboratory space was provided by Professor D. Richard Brown in spinlab.
cost?
The main focus for the construction of the ClusterFLOP was maximizing the Performance to Cost ratio. This would be expressed as gigaflops per dollar. In our case, the cluster cost approximately $450 and achieves about 2 gigaflops of computing power. The table below compares our system to a couple of others listed on the TOP500 Supercomputers list.
| TOP 500 Rank | Name | Location | Max. Performance (GFLOPS) | Cost ($) | FLOPS/$ |
| 1 | Earth Simulator | Japan | 35,860 | 350M | 0.10M |
| 3 | X | Virginia Tech. | 10,280 | 5.2M | 1.98M |
| ClusterFLOP | spinlab@WPI | 2 | 450 | 4.44M |
The Earth Simulator has been in first place for a couple of years. Virginia Tech's "X" Cluster was in third place, temporarily removed from the most recent list due to hardware updates. As can be seen from the above table, the Performance to Cost ratio that we achieved is more than twice that of the "X" cluster, the number 3 supercomputer, and about 44 times that of the Earth Simulator, currently the number 1 supercomputer in the world.
results?
We used POV-Ray in conjunction with a parallel POV-Ray script that we wrote and the time command to perform multiple tests with varying numbers of connected nodes. We rendered a simple repetitive tile image, thus minimizing the range of processing difficulty amongst the partial renders. The final image has a resolution of 9 1024 by 768 pixels with 8X antialiasing. We started testing with nine nodes connected and one by one, removed nodes from the system, in each case performing the test three times and averaging the results. This way, we ended up with a mean render time for each of one through nine connected nodes. In addition, as a comparison, we rendered the same image three times on an AMD Athlon XP 2800+ (2.08GHz) based computer running the same Debian Linux kernel. The results of this test are shown below.
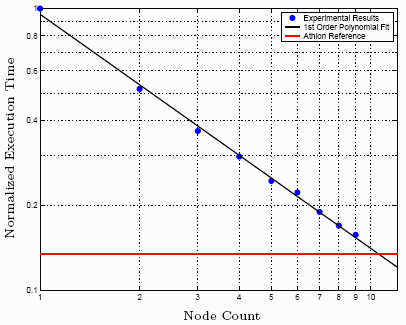
The resulting execution times shown above as blue dots are normalized to the length of time that a single node takes to render the image (e.g. - rendering an image using four nodes takes roughly 30% of the time that it takes a single node to render the same image). The relationship between execution time and the number of nodes is exponentially decreasing and so the data is plotted logarithmically so that it appears roughly linear. As a reference, the relative completion time for the Athlon is shown as a red bar. Using the polyfit function in Matlab, we generated a first order polynomial equation that is shown in black. More details can be found in the report.
how?
For further information concerning the implementation of the specific hardware and software as well as the testing techniques and results, read the report about the ClusterFLOP. Please feel free to contact any of the people involved at the indicated email addresses.
View the report: ClusterFLOP.pdf
next?
Unfortunately, a major impediment to achieving higher performance with the ClusterFLOP was the discovery that the embedded 800 MHz processor motherboards we purchased have a floating point unit (FPU) that is limited to 1/4 the speed of the processor (200 MHz). Without this problem, our achieved performance of 2 gigaflops would have had a theoretical maximum of 8 gigaflops instead. Our intention is to obtain consumer grade parts, instead of the lower end components we used on a graduate student budget, to build a ClusterFLOP II. We hope that manufacturers will be open to the idea of donating motherboards and processors to our lab, especially since we are specifically NOT interested in the latest and greatest items; but instead just 'run of the mill' parts. (Some 2 GHz processors, such as AMD Athlon XP 2500s, or Intel 1+ GHz Tualatins, with accompanying motherboards and RAM would be great.)
If you are interesting in donating equipment or funds, or just wish to offer some advice or ask a question, please feel free to contact any of the people involved, mentioned above.